この記事は「翻訳メモリの使い方 2. 似たような文を翻訳してみよう」の続編です。
※この記事は約30分で読めます。
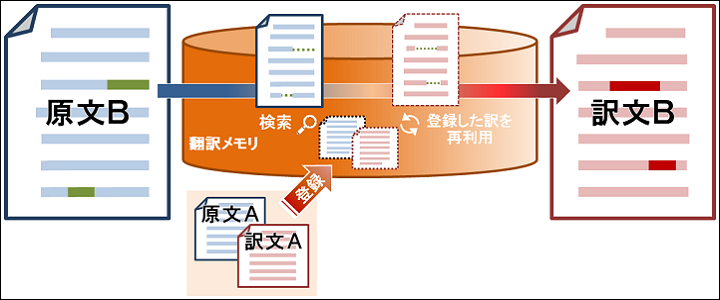
翻訳メモリ とは、原文と訳文のセットをデータベースに登録しておき、 次に似たような文が出現したときに文章の骨格を使いまわすことで効率的に翻訳する機能のことです。
前回は翻訳メモリ登録した文と似た文を効率よく翻訳する「自動文型一致文検索」について説明しました。自動文型一致文検索は変化した部分を自動で認識し、訳に当てはめてくれる非常に便利な機能ですが、前回の「補足」で例示したように自動で差異を認識するためには条件があり、万能というわけではありません。また変化する箇所が増えると類似度(一致率)が下がり、翻訳メモリの適用が困難になる場面も出てくるでしょう。
第3回では、翻訳メモリに登録する文を「文型」として指定することで変化する箇所を明示し、今後の翻訳に応用する方法について説明します。
(注意:)
- 翻訳メモリは一度登録すれば日→英、英→日の両方で利用できます。また、登録方法は日→英、英→日で共通です。
- 下記の翻訳結果は一例です。学習状況や使用している辞書など、お使いの環境によって異なる訳となる場合があります。
- 翻訳メモリはTranserシリーズ(Professional)および翻訳ブレインの機能です。翻訳ピカイチおよびTranser(Personal)、明解翻訳ではご利用いただけません。
1. 自動文型一致文検索できない場合
たとえばまず次の文を行番号1に入力し、そのまま翻訳メモリ登録してみましょう。
原文A:
先月、新王の即位の儀式が王宮にて厳粛に執り行われました。
訳文A:
Last month, the enthronement ceremony of the new King was held solemnly at the royal palace.
以下の文が翻訳メモリに登録されました。
【対訳文A】
日本文:
先月、新王の即位の儀式が王宮にて厳粛に執り行われました。
英文:
Last month, the enthronement ceremony of the new King was held solemnly at the royal palace.
|
念のため、翻訳メモリに登録する方法を復習します。
|
続いて、先ほど登録した対訳文Aが活用できることを期待して、文番号2に以下の文を入力し、翻訳してみましょう。
この例では「即位の儀式」を「戴冠式」に変えてみました。
原文B:
先月、新王の戴冠式が王宮にて厳粛に執り行われました。
ところが、翻訳結果は以下のとおりになりました。
訳文B‘:
The coronation of the new King was held solemnly last month in the royal palace.
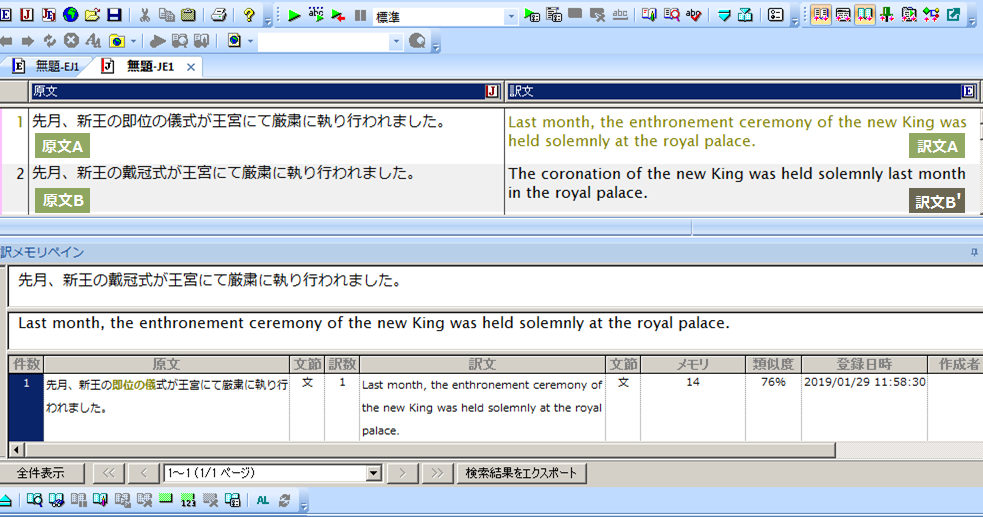
原文Aの「即位の儀式」を「戴冠式」に変更した原文Bを翻訳した状態。
翻訳メモリの自動文型一致文検索が適用されず、機械翻訳されました(訳文B‘)。
翻訳メモリペインで原文Bを類似文検索すると、対訳文Aとの類似度が76%であることが分かります
対訳文Aによる自動文型一致文検索が適用されず、訳文は機械翻訳されたことを示す黒い文字で表示されました。原文Bは対訳文Aの日本文にある「即位の儀式」を「戴冠式」に変えただけであり、類似度は76%と翻訳メモリが適用できる条件を満たしているにもかかわらず、翻訳メモリが適用されなかったことがわかります。なぜでしょうか。
それは、対訳文Aの中で、日本文の「即位の儀式」に相当する英文の訳語「enthronement ceremony」が、PC-Transerの辞書に存在しないためです。PC-Transerは原文Bが翻訳メモリAの日本文とよく似ており、「即位の儀式」が「戴冠式」に変化しているというところまでは気づいているはずですが、変化した箇所である「即位の儀式」に対応した訳語を英文の中から見つけられず、置換すべき箇所を特定できませんでした。
自動文型一致文検索は単純に[原文-訳文]の間にある[単語-訳語]の関係性をもとに、置換する語を決定するため、「変化する箇所の語が対訳文の日本文・英文の双方に存在し、一対一で辞書対応している」場合でないと適用されません。類似度が高くても、対訳文Aのセットを流用した訳文作成ができないと判断したPC-Transerは、翻訳メモリを使用しない通常の機械翻訳を行い、訳文B‘を生成しました。
同様に、他の例を見てみましょう。以下の文を翻訳メモリに登録します。
【対訳文C】
日本文:
小麦粉100g、砂糖100g、牛乳80ccを用意し、小麦粉は常温に戻して使用する。
英文:
Prepare 100g of flour, 100g of sugar and 80cc of milk, and bring back the flour to room temperature.
登録後、次の文を翻訳してみましょう。
原文D:
小麦粉100g、砂糖100g、牛乳80ccを用意し、牛乳は常温に戻して使用する。
期待する訳文:
Prepare 100g of flour, 100g of sugar and 50cc of milk, and bring back the milk to room temperature.
しかし翻訳結果は以下のようになります。
訳文D:
I prepare 100 g of flour, sugar 100 g, milk 80cc and I get the milk back to normal temperature and use it.
先ほどと違い、 “小麦粉” の訳語である “flour” は訳文中に存在しますが、自動文型一致文検索は適用されませんでした。理由は、「 “flour” が2語存在し、どちらの “flour” を “milk” に置換するか判断できなかったから」です。
今回の場合は対訳文の英文に “flour” が2語ずつ存在します。そのせいでPC-Transerはどちらの “flour” を “milk” に置き換えるべきかを判断できず、自動文型一致文検索による翻訳メモリの使用を断念して通常の機械翻訳が行われました。

「小麦粉」が「牛乳」に変化したため、翻訳メモリから検索された訳文にある「flour」を「milk」に差し替えようとしましたが、翻訳メモリは文脈を読まないため、どちらのflourをmilkに変えるべきかを判断できません。
翻訳メモリはどのような原文・訳文のペアでも登録できる柔軟性を持ちますが、登録したい対訳文は機械翻訳を行った逐語訳とは違い、必ずしも原文・訳文間で各単語が紐づいているわけではありません。しかしこのような文でも、変化しがちな箇所をあらかじめ指定しておき、原文の変化に対する訳文の対応箇所を登録しておけば、翻訳メモリは対応を見誤らずに翻訳を行うことができます。次の段では、変化する部分を明示するべく「タグ」を使用した翻訳メモリの登録方法をご案内します。
2. 文型一致文検索:タグを使用した翻訳メモリの登録と翻訳
もう一度、対訳文Aに戻ってご覧ください。
【対訳文A】
日本文:
先月、新王の即位の儀式が王宮にて厳粛に執り行われました。
英文:
Last month, the enthronement ceremony of the new King was held solemnly at the royal palace.
先ほどの例では、「即位の儀式」が「enthronement ceremony」と結びつかないことが原因で、自動文型一致文検索ができませんでした。
そこで、今回はこの双方を「お互いに関係している箇所」として紐づける作業を行います。明示するために使用するのは「タグ」と呼ばれる記号です。
翻訳メモリペインをご覧ください。先ほど登録する際に使用した原文Aと訳文Aが表示されています。
(表示されていない場合は、原文Aをクリックしてカーソルを置き、[カレント文の選択] をクリック(Ctrl+G、または[翻訳メモリ]メニュー>[カレント文の選択]を実行します)
をクリック(Ctrl+G、または[翻訳メモリ]メニュー>[カレント文の選択]を実行します)
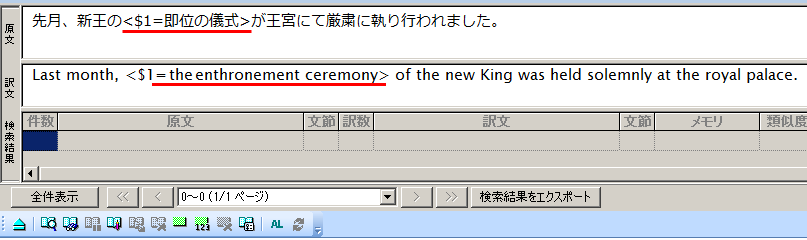
まず、翻訳メモリペインの原文エリアにある文のうち「即位の儀式」をドラッグして選択し、翻訳メモリツールバーの[タグ指定]  をクリック(Ctrl+I、または[翻訳メモリ]メニュー>[タグ指定]を実行)します。
をクリック(Ctrl+I、または[翻訳メモリ]メニュー>[タグ指定]を実行)します。
![タグ指定したい箇所を選択し、[タグ指定]をクリック](https://www.crosslanguage.co.jp/blog/wp-content/uploads/2019/01/tm3_tagging_01.png)
タグ指定したい箇所を選択し、[タグ指定]をクリック
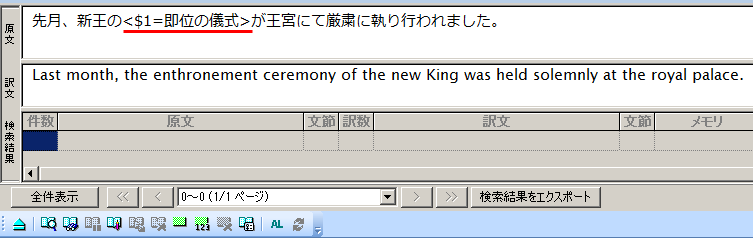
選択した箇所がタグ記号< >で囲まれてタグ指定されました
さらに、翻訳メモリペインの訳文エリアにある文のうち「the enthronement ceremony」をドラッグして選択し、同じように翻訳メモリツールバーの[タグ指定] をクリック(Ctrl+I、または[翻訳メモリ]メニュー>[タグ指定]を実行)します。
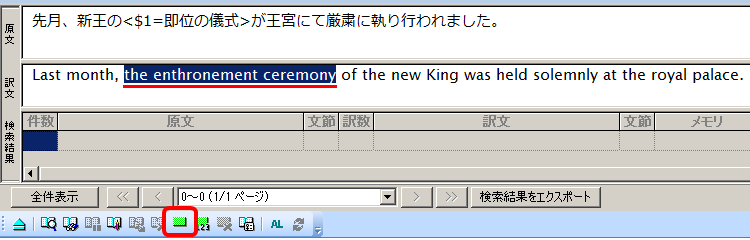
原文でタグ指定した箇所に相当する訳文の箇所をタグ指定します
これで、原文・訳文双方の対応する箇所にタグが指定されました。
原文と訳文にタグ指定を行うことで、変化する箇所を明示しました
ついでに、他の対応箇所も選択して順にタグ指定してみましょう。$1、$2などの数字は、対応する各タグが日本文と英文でお互い関係があることを示します。文中に設定するタグの並び順に制限はありませんが、原文と訳文が対応する箇所がペアになるよう、注意して指定してゆきます。
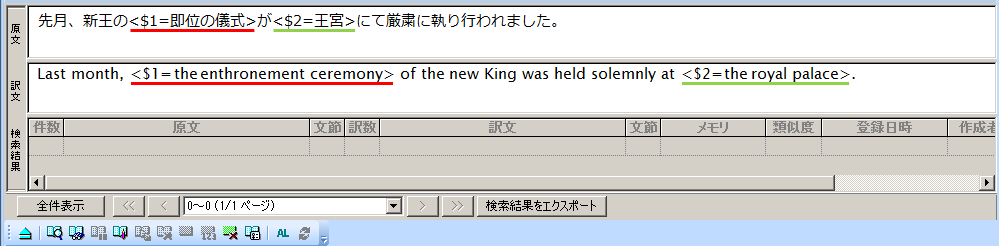
タグは1文中に10箇所まで指定できます。図では分かりやすいように色を変えてあります
タグは1文に10箇所まで指定可能です。想定される変化に応じ、対応する箇所がペアになるようにタグを指定してゆきます。
タグは手入力でも入力や編集が可能ですので、原文と訳文で一対一になるよう注意して入力します。
なお、位置を間違えてタグ指定してしまった場合は、タグを入力してしまった位置のどこかをクリックしてから、翻訳メモリツールバーの[タグ削除] をクリックする(または[翻訳メモリ]メニュー>[タグ削除]を実行)ことで、指定したタグを削除できます。今回は1文中にタグを3箇所設定しました。
をクリックする(または[翻訳メモリ]メニュー>[タグ削除]を実行)ことで、指定したタグを削除できます。今回は1文中にタグを3箇所設定しました。
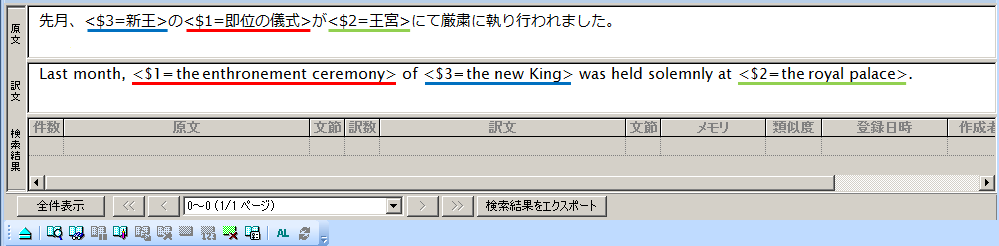
文中のタグの並びは自由ですが、原文と訳文でタグ番号が一対一で対応している必要があります
指定できたら、翻訳メモリに登録しましょう。[翻訳メモリ]ツールバーの[登録] をクリック(Ctrl+R、または[翻訳メモリ]メニュー>[対訳文を確定]を実行)し、確認画面にて[登録]すると翻訳メモリへの登録が完了します。
をクリック(Ctrl+R、または[翻訳メモリ]メニュー>[対訳文を確定]を実行)し、確認画面にて[登録]すると翻訳メモリへの登録が完了します。
【対訳文A+】
日本文A+:
先月、<$3=新王>の<$1=即位の儀式>が<$2=王宮>にて厳粛に執り行われました。
英文A+:
Last month, <$1=the enthronement ceremony> of <$3=the new King> was held solemnly at <$2=the royal palace>.
登録を終えたら、原文Bを再度翻訳してみましょう。文番号2のエリアをクリックしてください。
原文B:
先月、新王の戴冠式が王宮にて厳粛に執り行われました。
訳文B:
Last month, the coronation of the new King was held solemnly at the royal palace.
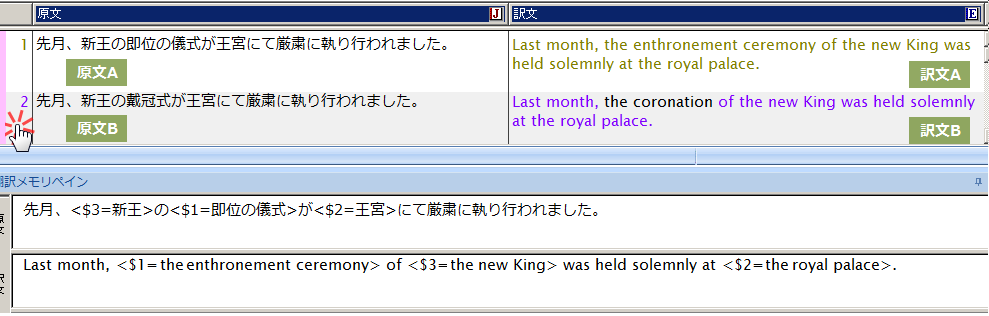
翻訳メモリ中の対訳文A+が有効にはたらき、文の骨格を流用しつつ 変化した部分は機械翻訳して出力されました
今度の翻訳では翻訳メモリが使用され、対訳文A+をもとにした訳が生成されました。
対訳文A+を流用した部分は紫色の文字、タグ指定した箇所は機械翻訳されて黒い文字として表示されています。このように、変化すると予想される箇所をあらかじめ原文と訳文の両方にタグ指定しておき、次の翻訳に役立てる翻訳メモリの登録・検索方法を「文型一致文検索」と呼びます。また、タグを使用しない通常の文に対し、タグを使用して記述した文を「文型」と呼びます。
同じように、タグ指定した他の部分も変化させて翻訳してみましょう。
原文C:
先月、聖火の採火がオリンピアにて厳粛に執り行われました。
訳文C:
Last month, lighting torch of the Olympic Flame was held solemnly at Olympia.
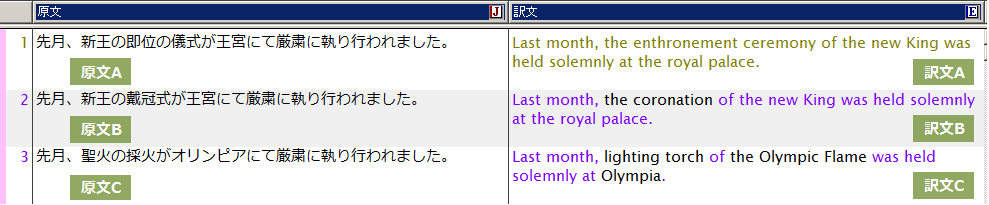
変化する部分が増えても、翻訳メモリの骨格を使いながらタグ指定した箇所を機械翻訳して出力します
変化する箇所を複数指定したことで、文の要素をかなり変化させても柔軟に追随して翻訳できるようになりました。
自動文型一致文検索では変化する語と訳語の間に辞書対応がないと適用できないことから、文学的表現や慣用句などが入り混じった文の応用がどうしても苦手です。これに対してタグ指定による文型一致文検索では変化する箇所を明示し、文を「型」として登録することで、似た文を翻訳する場合に翻訳メモリの適用が受けやすくなります。変化が予想される場所が明確なため検索も速く、また文型一致文検索は一致率の制限を受けないという利点もあります。
3. タグを含んだ文の構造
たとえば以下の文を翻訳メモリ登録するとします。
原文:
For further details of the initial configuration dialog, see Chapter 2.
訳文:
初期設定ダイアログの詳細については第2章を参照せよ。
変化しそうな部分をタグ指定し、翻訳メモリ登録してみましょう。今回は以下のようにタグ指定します。
【対訳文D+】
英文:
For further details of <$1=the initial configuration dialog>, see Chapter <$2=2>.
日本文:
<$1=初期設定ダイアログ>の詳細については第<$2=2>章を参照せよ。
< > の記号で囲まれた部分をタグと呼びます。また上記の例では<$1=初期設定ダイアログ>、<$2=2>など、タグ指定の際に選択した部分が ” = ” に続くかたちで込められています。この箇所はタグ内の例文と呼び、タグ指定する際に、元となった語も同時に記録しておく意味合いがあります。
タグは英文・日本文の両方で、一対一で対応している必要があります。片方が欠けると翻訳メモリには登録できません。また、複数のタグを連続して配置することはできません。
タグ内には例文だけでなく、変化する内容や属性を指定・制限するための情報を付与することも可能です。たとえば上記の例で<$2=9>タグに入る語を数字だけに限定したい場合は、タグ指定の際に[翻訳メモリ]ツールバーの[数値タグ指定] をクリック(Ctrl+N、または[翻訳メモリ]メニュー>[数値タグ指定]を実行)するか、タグを<$2#NUM=9>のように記述します。
をクリック(Ctrl+N、または[翻訳メモリ]メニュー>[数値タグ指定]を実行)するか、タグを<$2#NUM=9>のように記述します。
タグに関する様々な設定はここでは語りきれません。詳細はユーザーズ・ガイドの「翻訳メモリ」の項目にて、「文型とタグ」をご覧ください。
4. 自動文型一致文検索と文型一致文検索を併用する
本エントリでは変化した部分を明示して機械翻訳させるために、文にタグを指定して登録する方法をご案内しました。自動文型一致文検索と併用しつつ、より流用しやすいかたちで翻訳メモリ登録してゆくことが、その後の翻訳を効率化する上で重要になってきます。使いはじめのうちは地道に登録を続ける作業が続きますが、翻訳メモリを蓄積してゆくことでマッチする文例が徐々に増えてゆき、加速度的に効率が向上するはずです。
次回は、原文と似た文を翻訳メモリから検索し、見つかった訳文をそのまま表示する「類似文検索」について説明します。これまで登録してきた翻訳メモリが、別のかたちで活用できます。
なお、本エントリの内容はユーザーズ・ガイドの[翻訳メモリ]の項目にある[ユーザー翻訳メモリに対訳文を登録する]に詳述されています。
(「翻訳メモリの使い方 4. 類似文検索を使用する」 に続きます)
補足
文型一致文検索で翻訳された文のうち、機械翻訳された部分はダブルクリックしても訳語変更ができません。
該当箇所の語を学習させれば、文型一致文検索でも機械翻訳部分に学習した訳語を使用するため、この場合は一旦機械翻訳したうえで訳語学習し、その後に翻訳メモリによる翻訳を行うことで解決します。手順は以下のとおりです。
- 文型一致文検索で生成された訳文中にある機械翻訳された箇所のうち、学習させたい語の目星をつけておきます。
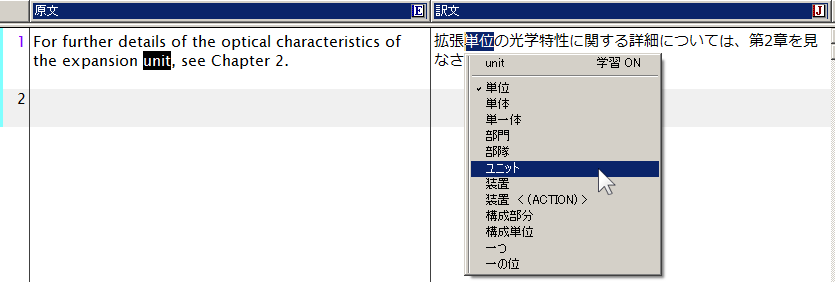
この例の場合ではunitを「ユニット」と訳したいところが、そのままの訳では「単位」と直訳されています。

機械翻訳部分の「単位」を「ユニット」と訳語変更したいのですが
翻訳メモリを使用した翻訳結果では訳語変更できません
- Shiftキーを押しながら該当文の文番号をクリックします。こうすることで、翻訳メモリを使用しない(構文解析と辞書による)機械翻訳が行われます。

Shiftキーを押しながら文番号をクリックすると、翻訳メモリを使わない通常の機械翻訳を実施します
- 訳語変更やユーザー辞書登録を実施し、PC-Transerに訳語を学習させます。この例では「単位」をダブルクリックし、訳語の変更を実施します。
機械翻訳した文は訳語対応されているため、訳語変更が可能です。
また、ここでユーザー辞書登録を行うこともできます
- 改めて文番号をクリックして一文翻訳を行います。Shiftキーを押さずに翻訳すると、翻訳メモリを使用した結果となります。
学習済みの語が機械翻訳部分に反映され、求める訳が得られました。

文番号をクリックして翻訳します。
機械翻訳部分の訳が、学習された訳語に変わりました
内容についてご不明な点がございましたら、こちらのお問い合わせフォームにてお問い合わせください。
