(この記事は「翻訳メモリの使い方 1. 登録してみよう」の続編です)
※この記事は約20分で読めます。
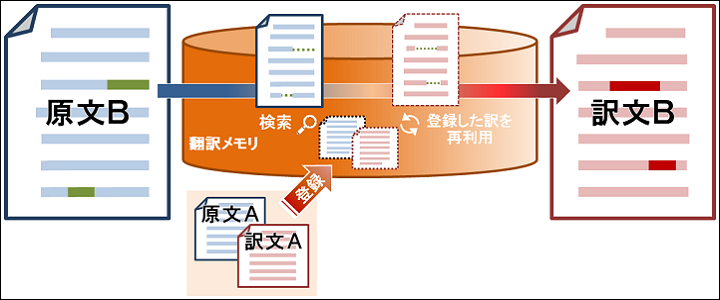
翻訳メモリ とは、原文と訳文のセットをデータベースに登録しておき、 次に似たような文が出現したときに文章の骨格を使いまわすことで効率的に翻訳する機能のことです。
前回は翻訳メモリ登録した文をそのまま使いまわし、次に全く同じ文が登場したときに同じ訳が出るようにする翻訳メモリの基本的な原理をご案内しました。しかし登録した原文をそのまま訳文として返すだけでは、ユーザー辞書の機能と変わりありません。
翻訳メモリの真価は、「似たような文書に柔軟に対応できる」点にあります。
本エントリでは「自動文型一致文検索」を使って、前回登録した翻訳メモリが類似の文にも応用できる実例をご覧いただきます。
(注意:)
- 翻訳メモリは一度登録すれば日→英、英→日の両方で利用できます。また、登録方法は日→英、英→日で共通です。
- 下記の翻訳結果は一例です。学習状況や使用している辞書など、お使いの環境によって異なる訳となる場合があります。
- 翻訳メモリはTranserシリーズ(Professional)および翻訳ブレインの機能です。翻訳ピカイチおよびTranser(Personal)、明解翻訳ではご利用いただけません。
1. 似たような文を翻訳してみる(自動文型一致文検索)
翻訳メモリに登録した文は、似たような構造の別の文を翻訳する際に使い回すことが可能です。前回の例ではマニュアル文を想定した対訳文を登録しました。
(登録手順は「翻訳メモリの使い方 1.登録してみよう」の「2. 翻訳メモリを登録してみる」の動画をご覧ください)
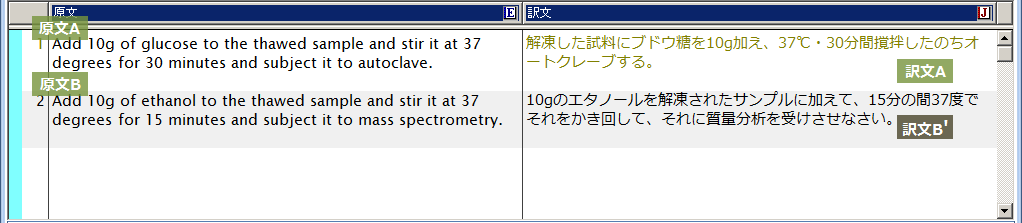
<前回翻訳メモリ登録した対訳文>
原文A:
Add 10g of glucose to the thawed sample and stir it at 37 degrees for 30 minutes and subject it to autoclave.
訳文A:
解凍した試料にブドウ糖を10g加え、37℃・30分間撹拌したのちオートクレーブする。

前回翻訳メモリ登録した対訳文
今回はこれとよく似ている文を翻訳し、翻訳メモリの動作をご覧いただきます。
なお事前の設定として、「自動文型一致文検索」機能をオンにしておく必要があります。
[翻訳]メニュー>[翻訳設定]>[翻訳]タブ>[訳文生成方法(優先順)]にて「完全一致文検索」「文型一致文検索」に加え、「自動文型一致文検索」にチェックを入れ、[OK]してください。
(部分完全一致文検索、部分文系一致文検索、類似文検索はまだチェックを入れないでください)
![[翻訳]メニュー>[翻訳設定]>[翻訳]タブ>[訳文生成方法(優先順)]にて「自動文型一致文検索」をチェックします](https://www.crosslanguage.co.jp/blog/wp-content/uploads/2019/01/auto_match.png)
[翻訳]メニュー>[翻訳設定]>[翻訳]タブ>[訳文生成方法(優先順)]にて
「自動文型一致文検索」をチェックします
” glucose” を “ethanol” 、”30 minutes” を “15 minutes” 、”autoclave” を “mass spectrometry” に変更しました。
原文B:
Add 10g of ethanol to the thawed sample and stir it at 37 degrees for 15 minutes and subject it to mass spectrometry.
翻訳結果は以下のようになります。
訳文B:
解凍した試料にエタノールを10g加え、37℃・15分間撹拌したのち質量分析する。

翻訳メモリに登録した対訳文が応用され、滑らかな翻訳結果となりました
前回翻訳メモリに登録した対訳文(文番号1)が応用された、滑らかな翻訳結果となりました。訳文のうち翻訳メモリから流用した部分は「自動文型一致文検索」を示す水色で、機械翻訳した部分は黒く表示されています。
このように、翻訳メモリは登録された文の骨格を流用しつつ、変化した部分を別途翻訳して元の文に当てはめることで、似たような文に柔軟に対応できる自動文型一致文検索と呼ばれる検索機能を持っています。この機能により、一度作りこんだ完成訳をどんどん蓄積してゆけば、次に似たような文が出てきたときにスムーズな翻訳が出力されることになり、また文体を統一することもできます。このように翻訳メモリは、似たような言い回しが多い法務文書や、バージョンアップのたびにわずかな違いが発生してその都度翻訳しなおす必要のあるマニュアル文書などに、特に力を発揮します。
参考として、通常の機械翻訳を行った場合の訳文もご覧ください。
通常の機械翻訳を行った場合(訳文B‘):
10gのエタノールを解凍されたサンプルに加えて、15分の間37度でそれをかき回して、それに質量分析を受けさせなさい。
2. 自動文型一致文検索の仕組み
PC-Transerはまず翻訳メモリを検索し、対象の文と似たような原文が登録されていないか探します。類似した文(原文A)が見つかると、PC-Transerは双方の文を比較し、共通する部分・相違する部分を抽出します。
原文B:
Add 10g of ethanol to the thawed sample and stir it at 37 degrees for 15 minutes and subject it to mass spectrometry.
翻訳メモリを検索して見つかった類似の文(原文A):
Add 10g of glucose to the thawed sample and stir it at 37 degrees for 30 minutes and subject it to autoclave.
続いて訳文Aを参照し、原文で変化した箇所に相当する箇所を類推します。
原文Aに対応する訳文(訳文A):
解凍した試料にブドウ糖を10g加え、37℃・30分間撹拌したのちオートクレーブする。
こうして抜き出した共通部分から、流用する原文A・訳文Aの骨格が出来上がります。
相違点をもとに、原文Aとの共通部分を抽出:
Add ( 1 ) of glucose to the thawed sample and stir it at 37 degrees for ( 2 ) minutes and subject it to ( 3 ).
訳文を解析し、共通する部分を抽出:
解凍した試料に( 1 )のブドウ糖を加え、37℃・( 2 )分間撹拌したのち( 3 )する。
ここまでできれば、後は()に相当する箇所を原文Bから借り、個別に機械翻訳して当てはめるだけとなります。
原文Aをもとに抽出した訳文Aの共通部分に、原文Bが持つ相違点を機械翻訳して当てはめた訳文(訳文B):
解凍した試料にエタノールを10g加え、37℃・15分間撹拌したのち質量分析する。
こうして、翻訳を開始して1秒と待たずに訳文Bが完成しました。登録した翻訳メモリの大まかな文体を参考にしながら、変化した部分だけが別に訳されて元の文にうまく組み込まれていることがお分かりいただけるかと思います。
3. 翻訳メモリの類似度(一致率)
原文Bをもう少し変化させて翻訳してみるとどうなるでしょうか。
下の例では、”10g” を “150mg” に、”37 degrees” を “20 degrees” に変更しました。
原文C:
Add 150mg of ethanol to the thawed sample and stir it at 20 degrees for 15 minutes and subject it to mass spectrometry.
翻訳結果は以下のようになります。
訳文C’:
150mgのエタノールを解凍されたサンプルに加えて、15分の間20度でそれをかき回して、それに質量分析を受けさせなさい。

原文Cは原文Aと「似ていない」と判定され、通常の機械翻訳が実施されました
原文Cと原文Aとの類似度はさらに下がったことから、今度は「原文Aと原文Cは翻訳メモリが適用できるほど似ていない」と判断され、通常の機械翻訳が実行されました。
翻訳時に翻訳メモリを適用するかどうかを判定する指標として「類似度」があります。類似度は、「翻訳しようとする文」が「翻訳メモリに登録されている文」とどの程度似ているかを、語の一致率(%)で表したものです。
初期設定では、原文との類似度(一致率)が70%以上の翻訳メモリを翻訳に使用するよう設定されており、類似度70%未満の翻訳メモリは「似ていない文」として使用せず、機械翻訳を行うようになっています。上の例では、いちばん類似していると思われる原文Aとの比較でも一致率が70%を下回ったために、機械翻訳が実施されたということになります。
しかし原文Aと原文Cでは、翻訳に流用できる部分がかなりあります。一致率を変更し、翻訳メモリがマッチする度合いを高めましょう。
設定は[翻訳メモリ設定]で行います。
[翻訳メモリ]メニュー>[設定]>[検索オプション]タブにて「一致率」のスライドを70%から50%に変更し、[設定]してください。
![[翻訳メモリ]メニュー>[設定]>[検索オプション]タブにて 「一致率」のスライドを70%から50%に変更します つまみをドラッグするか、付近をクリック後にキーボードの← →キーでも変更できます](https://www.crosslanguage.co.jp/blog/wp-content/uploads/2019/01/tm_match_rate.png)
「一致率」のスライドを70%から50%に変更します。
つまみをドラッグする/つまみをクリック後にキーボードの← →キーを押して変更します
訳文C:
解凍した試料にエタノールを150mg加え、20℃・15分間撹拌したのち質量分析する。

一致率を下げると、翻訳メモリが適用された翻訳結果が得られました
念のため、原文Aと原文Cの一致率がどれくらいなのか、比較してみましょう。
原文Cにカーソルを置き、ツールバーの[カレント文の選択] をクリック(またはCtrl+G)すると、翻訳メモリペインに原文Cと訳文Cが取り込まれます。
をクリック(またはCtrl+G)すると、翻訳メモリペインに原文Cと訳文Cが取り込まれます。
翻訳メモリペインの[類似文検索] をクリック(またはCtrl+Shift+L)すると、翻訳メモリから原文Cに近い原文Aが検索され、検索結果表示エリアに表示します。
をクリック(またはCtrl+Shift+L)すると、翻訳メモリから原文Cに近い原文Aが検索され、検索結果表示エリアに表示します。
検索結果の「類似度」から、原文Cは原文Aに対して60%の類似度であることが見て取れます。
翻訳メモリの検索対象となる基準値を初期値の70%から50%まで下げたことにより、先ほどは適用されなかった類似度60%の翻訳メモリが適用できるようになったことが、お分かりいただけるかと思います。
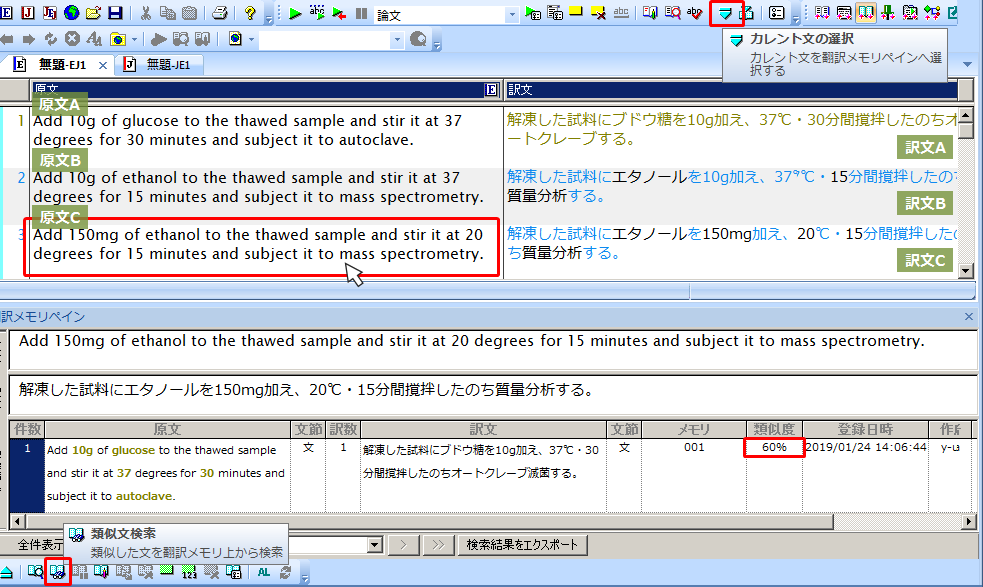
一致率を下げたことにより、先ほどは検索できなかった翻訳メモリがマッチするようになった例。
翻訳メモリペインで確認すると類似度が60%であることがわかります
翻訳メモリの一致率は初期設定では70%にしてありますが、上記のように一致率を変えることで適用の範囲を広げたり狭めたりすることが可能です。
一致率を下げることで検索の漏れは少なくなり、より柔軟な適用が可能になりますが、検索(翻訳)にかかる速度は遅くなります。
次回は、変化する部分を明示して翻訳メモリに登録する方法をご案内します。
なお、本エントリの内容は、ユーザーズ・ガイドの[翻訳メモリ]の項目にある[ユーザー翻訳メモリに対訳文を登録する]に詳述されています。
(「翻訳メモリの使い方 3.変化する箇所を明示する」 に続きます)
補足<1> <2>
内容についてご不明な点がございましたら、こちらのお問い合わせフォームにてお問い合わせください。 |