こんにちは、私はクロスランゲージという会社でルールベース機械翻訳やニューラル機械翻訳システムの機械翻訳エンジンを開発しているニャマといいます。機械翻訳を開発するエンジニアとして、最近AIの進化にともない注目度が高い機械翻訳について、その仕組みをご紹介します。
はじめに

AI(人工知能)は、ディープラーニング(Deep Learning:深層学習)の登場により第3次ブームに入ったと言われており、画像認識、音声認識や機械翻訳も含む自然言語処理など様々な分野でAIが大活躍するようになりました。2016年9月、Googleが、ディープラーニングを使ったニューラル機械翻訳サービスを発表し、その機械翻訳の翻訳精度が劇的に向上したことが大きな話題になりました。
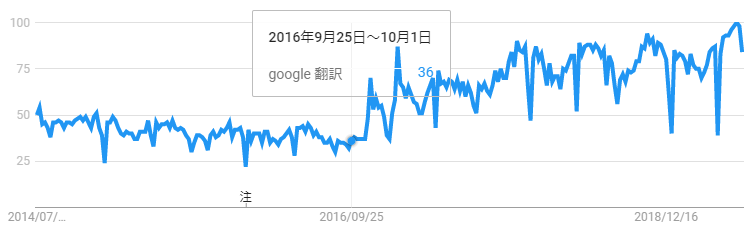
Googleトレンドからも「Google翻訳」というキーワードが検索される件数が2016年9月以降増えていることが分かります。そして、このタイミングから機械翻訳の分野においては、ニューラル機械翻訳が一気に広がりはじめました。
そもそも機械翻訳の歴史は古く、1933年にロシア人技術者により機械翻訳特許が出願されています。それ以降、機械翻訳の手法は、①ルールベース機械翻訳(Rule Base Machine Translation、通称RBMT)、②統計的機械翻訳(Statistical Machine Translation、通称SMT)、③ニューラル機械翻訳(Neural Machine Translation、通称NMT)と段階を踏んで進化してきました。
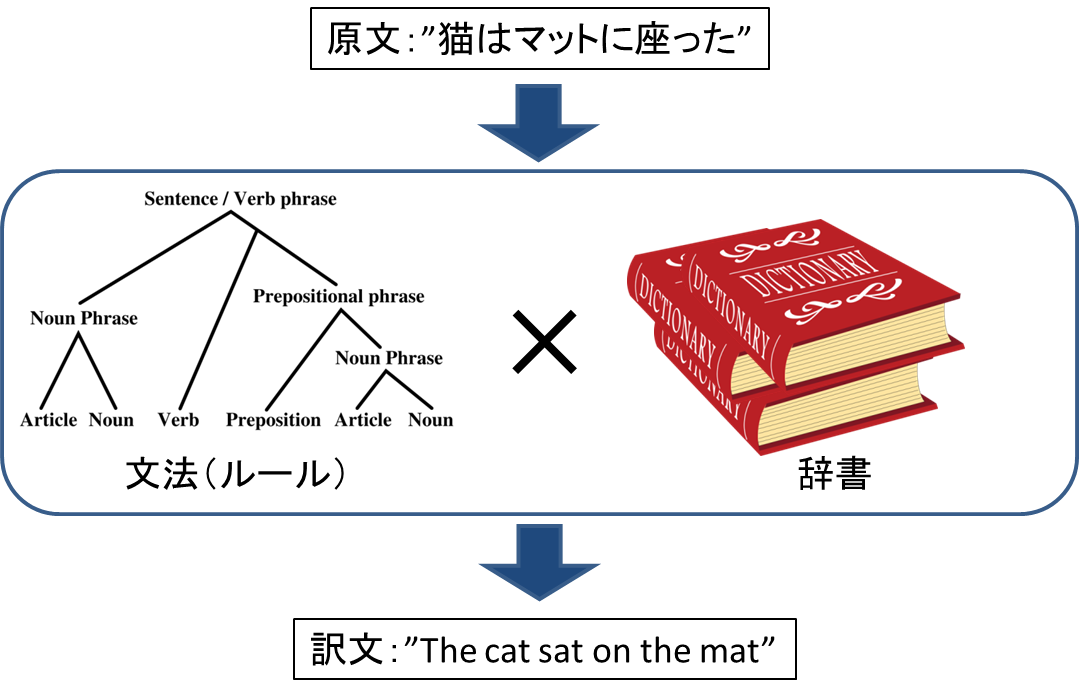
① ルールベース機械翻訳(RBMT)
RBMTは数十年前から開発されており、機械翻訳の手法としては一番歴史が長いものです。1954年にジョージタウン大学などの研究グループが機械翻訳システムを発表したことで、形態素解析や係り受け解析などのRBMTに必要な技術の研究がはじまりました。RBMTの手法を一言で表すと、人間が予め作った文法ルールと辞書情報を照らし合わせながら訳文を生成するというものです。そのため開発者に高度な言語知識が求められ、翻訳精度向上のためには莫大な人手の作業時間がかかるものでした。
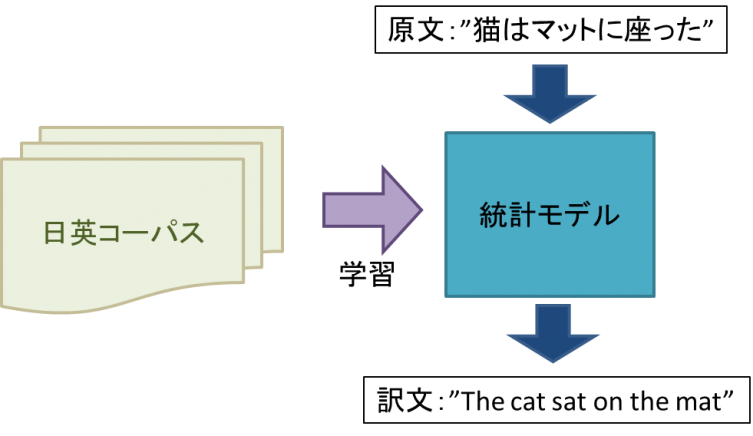
② 統計的機械翻訳(SMT)
1990年代にIBMが異なる言語間の単語を統計的に対応させる「IBMモデル」という手法を提案し、これがSMTの始まりになりました。SMTでは「コーパス」と呼ばれる大量の対訳データ(原文データとそれを人間が翻訳した訳文データの対データ)を学習データとして与え、コンピュータに統計モデルを学習させます。そしてその統計モデルを使って訳文を生成させます。1単語の前後にある単語を含めて翻訳するため、組み合わせの確率が高いものが訳文として生成されます。大量のコーパスを用意してモデルに学習させる必要がありますが、コーパスと学習プログラムがあれば学習自体はコンピュータが行うため人手はかかりません。
③ ニューラル機械翻訳(NMT)
ニューラル機械翻訳(NMT)では、ニューラルネットワークにディープラーニングを適用しています。ニューラルネットワークとは脳機能に見られるいくつかの特性を模擬した数理的モデルで、1957年考案されたパーセプトロンがその始まりです。ディープラーニング以前のニューラルネットワークでは勾配消失や局所最適解に陥るなどの問題があり、十分学習できませんでした。しかし、計算機の性能向上とWeb発達による学習データ調達の容易化によって多層ニューラルネットワーク(Deep Neural Network)の研究が盛んに行なわれるようになりました。
ディープラーニングを利用したアプリケーションは、1990年代に音声認識の分野で最初に登場し、機械翻訳におけるニューラルネットワークの使用に関する最初の学術論文は2014年に発表されました。SMTでは言語モデル、翻訳モデル、並び替えモデルといった複数のモデルが存在しますが、NMTでは、1つのエンドツーエンド(end-to-end) モデルだけ学習されます。NMTでは文全体の情報を文脈として扱えることで、語順や構造が異なる言語間でも高い翻訳精度に達しています。また人間が翻訳した文章を基に学習するので、訳文の特徴も学習し、生成される訳文も人間が書いたものに近い自然な文章になります。しかし、NMTの翻訳精度はニューラルネットワークのアーキテクチャ(計算モデル)と学習データに依存するため、学習データの量や質によっては、間違った翻訳結果を出力してしまうことがあります。
各手法の比較
| RBMT | SMT | NMT | |
| 訳文の特徴 | ・口語への対応が難しい ・訳文の表現が固い、不自然になることがある |
単語やフレーズ間の関係は抽出できるが、長文だと文全体の構造を上手く抽出できないことがある | ・自然な文章になる ・訳抜けや訳過多が起こることがある |
| 未知語対応 | 〇 (辞書登録で対応できる) |
△ (コーパス追加と再学習が必要) |
△ (コーパス追加と再学習が必要) |
| 訳抜けや訳過多 | 〇 | 〇 | ✕ |
| コーパス量 | 〇 | △ (大量に必要) |
△ (大量に必要) |
| 計算量 | 〇 | △ | △ |
| 開発コスト | ✕ | 〇 | 〇 |
| 多言語への対応 | ✕ (言語ごとに開発が必要) |
〇 (コーパスがあれば学習だけで展開できる) |
〇 (コーパスがあれば学習だけで展開できる) |
| 翻訳精度 | △ | △ | 〇 |
| 翻訳プロセスの制御 | 〇 | ✕ | ✕ |
このように各手法にそれぞれメリットとデメリットがあります。NMTは流暢で自然な訳文を生成しますが、原文すべてを正確に翻訳していない可能性があります。特に固有名詞や数字など正確さが求められるものについては注意が必要です。例えば、ある NMT方式の自動翻訳システムを利用したWebサイトで、大阪メトロ「堺筋線」の翻訳結果が「Sakai Muscle line」と誤訳になってしまっていたことがニュースになりました。この誤訳は、学習データに「堺」、「筋」、「線」それぞれの単漢字のデータ量が「堺筋線」より多かったことが原因と考えられます。人間でも初めて見る漢字を読むのが難しいのと同じように機械学習でも学習したことのない単語や文章について正しく翻訳するのは難しいということです。
この誤訳を修正するために、SMT、NMTでは新しく学習データを追加し、翻訳モデルを再学習する必要があります。ちなみにRBMTでは、辞書に単語を登録するだけ解決できます。
機械翻訳では言葉の意味を理解しません

機械翻訳の学習は単語間の前後関係や対訳関係を学習するもので、単語の意味までは学習しません。例えば人間は「リンゴ」という単語を聞くだけで実物のリンゴを想像し、リンゴは食べ物であることやその味、また色や形などリンゴの様々な特徴が浮かびます。人間は五感で体験したことや自分の行動に言葉を結びづけて学習します。一方機械学習では「リンゴ」という単語についてコーパスに現れる「美味しいリンゴ」や「リンゴを食べる」などの文章から他の単語やフレーズとの関係や「リンゴ→apple」という対訳関係しか学習しません。人間の翻訳者は翻訳をする際、文の意味を理解してから、それを別の言語で表現します。しかし、機械翻訳では前述のように、他の単語との関係や対訳関係を基に翻訳します。そのため、現在の機械翻訳では、人間と全く同じレベルの翻訳結果を期待することはできません。
翻訳の使い分け
機械翻訳はRBMT、SMT、NMTいずれも全ての文を100%正しく翻訳できるわけではありません。そのため、必要に応じて使い分ける必要があります。例えば、文や文章の内容をある程度流暢で意味が通るように翻訳を行いたい場合はNMT、正確さが重要な固有名詞や数字などが入っている文章ではRBMTを使い、どちらも要求される場合は人間の翻訳者に依頼したり、機械翻訳の結果を翻訳者にチェックしてもらうといった使い分け・組み合わせが望ましいです。また、機械翻訳を使う場合は、原文を簡潔であいまいな表現がない日本語(日本語から外国語へ翻訳する場合)にすると誤訳が少なくなる傾向があることもわかっています。
弊社の取り組み
弊社ではRBMTとNMTの両方について開発及び研究を行っております。最近では、新元号「令和」が発表された当日に、RBMTが得意とする「ルール作り」により、「令和〇〇年」の翻訳に対応いたしました。弊社が運営する無料翻訳サイトCROSS-Transerでぜひお試しください。![]()